Perceiving Copulas for Multimodal Time Series Forecasting
Abstract
Transformers have demonstrated remarkable efficacy in forecasting time series data. However, their extensive dependence on self-attention mechanisms demands significant computational resources, thereby limiting their practical applicability across diverse tasks, especially in multimodal problems. In this work, we propose a new architecture, called perceiver-CDF, for modeling cumulative distribution functions (CDF) of time series data. Our approach combines the perceiver architecture with a copula-based attention mechanism tailored for multimodal time series prediction. By leveraging the perceiver, our model efficiently transforms high-dimensional and multimodal data into a compact latent space, thereby significantly reducing computational demands. Subsequently, we implement a copula-based attention mechanism to construct the joint distribution of missing data for prediction. Further, we propose an output variance testing mechanism to effectively mitigate error propagation during prediction. To enhance efficiency and reduce complexity, we introduce midpoint inference for the local attention mechanism. This enables the model to efficiently capture dependencies within nearby imputed samples without considering all previous samples. The experiments on the unimodal and multimodal benchmarks consistently demonstrate a 20% improvement over state-of-the-art methods while utilizing less than half of the computational resources.
TL;DR: PrACTiS couples a Perceiver encoder with copula-based attention, plus midpoint inference, local attention, and output-variance testing to efficiently forecast multimodal time series with missing and asynchronous observations, achieving ~20% accuracy gains with < 50% memory usage compared to strong baselines.
1. Motivation
Time-series forecasting must jointly capture global trends and local variations while coping with missing values, asynchronous measurements, and multimodal inputs. Transformer-based models perform well but are often computationally expensive due to heavy reliance on self-attention, limiting scalability in high-dimensional and incomplete settings.
2. Proposed Approach – PrACTiS
PrACTiS is a hybrid architecture that combines a Perceiver encoder with a copula-based attention mechanism to model the joint distribution of observations and missing data. The Perceiver compresses complex, multimodal inputs into a compact latent space; the copula-based module captures inter-variable dependencies for robust imputation and forecasting.
- Perceiver encoder: tokenizes and projects inputs to a small latent array for efficient processing.
- Copula-based attention: represents the joint distribution across variables/time, improving handling of missingness.
- Midpoint inference: estimates intermediate values to better condition local dependencies.
- Local attention: restricts context to nearby windows to reduce compute and memory.
- Output variance testing: detects unstable predictions to curb error propagation during iterative decoding.
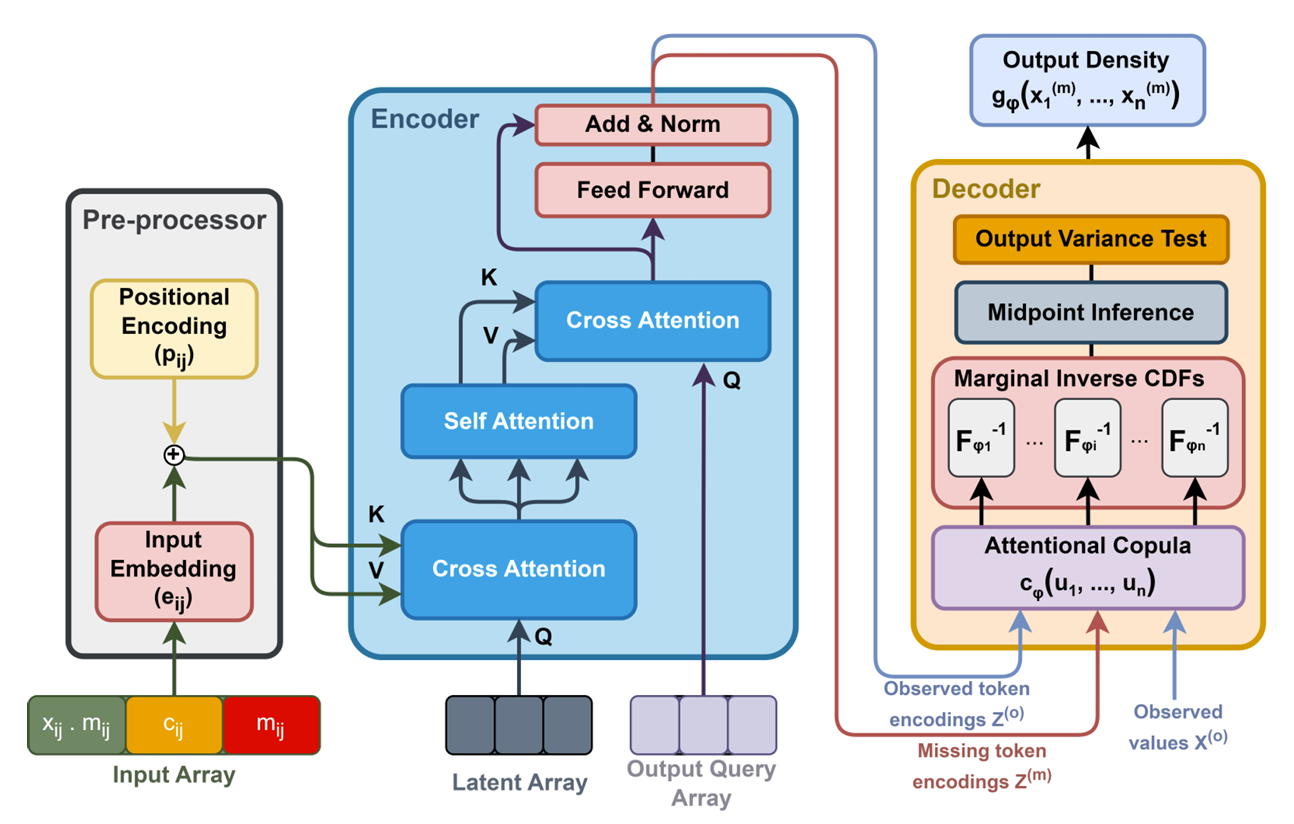 The overview architecture of PrACTiS.
The overview architecture of PrACTiS.
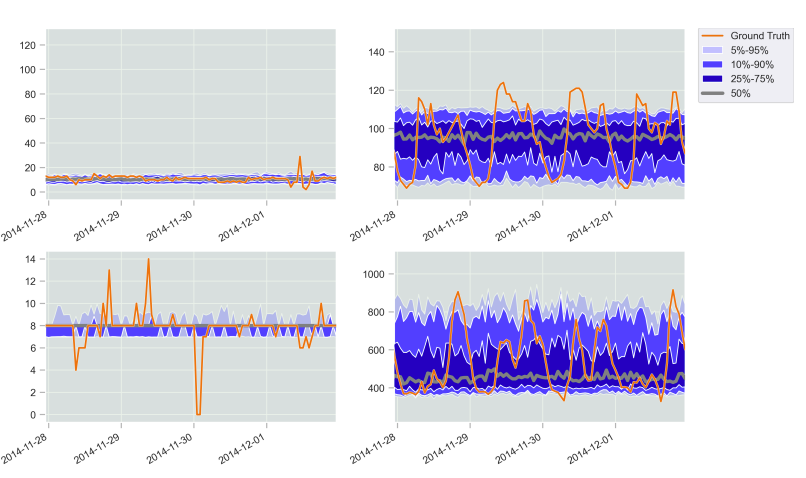 The predicted samples by TACTiS for one-month forecasts, corresponding to 672 time-steps, conditioned on one-month historical data
in electricity dataset.
The predicted samples by TACTiS for one-month forecasts, corresponding to 672 time-steps, conditioned on one-month historical data
in electricity dataset.
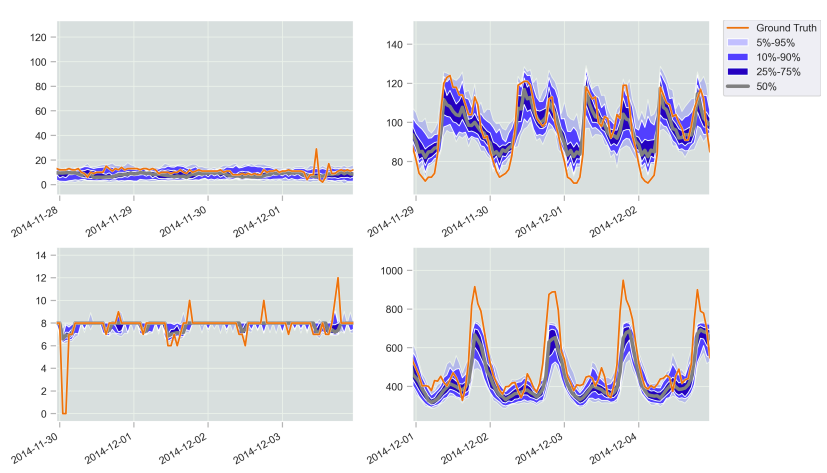 The predicted samples by PrACTiS for one-month forecasts, corresponding to 672 time-steps, conditioned on one-month historical data
in electricity dataset.
The predicted samples by PrACTiS for one-month forecasts, corresponding to 672 time-steps, conditioned on one-month historical data
in electricity dataset.
3. Technical Highlights
- Complexity: avoids the quadratic scaling of full self-attention by operating in latent space and using local attention.
- Multimodality: the Perceiver cleanly ingests heterogeneous inputs (e.g., sensors, categorical/continuous features).
- Missing data: copula-based attention explicitly models dependencies to impute and forecast when observations are sparse or asynchronous.
4. Results (High-Level)
Across unimodal and multimodal benchmarks, PrACTiS reports about a 20% accuracy improvement over strong baselines while using less than half the memory. Efficiency gains come from the Perceiver's latent bottleneck and local attention, without sacrificing accuracy on long sequences with missingness.
Key Contributions
- Introduces a hybrid architecture combining Perceiver and copula-based attention for time-series forecasting.
- Reduces computational complexity through latent space transformation and local attention mechanisms.
- Implements midpoint inference and output variance testing to handle missing data effectively.
- Achieves 20% performance improvement over state-of-the-art methods with reduced memory usage.
- The proposed method can be applied to wide domains include healthcare (irregular vitals), finance (asynchronous indicators), and IoT (multimodal sensors), where observations are often incomplete or misaligned.
Citation
@INPROCEEDINGS{10838953,
author={Le, Cat P. and Cannella, Chris and Hasan, Ali and Ng, Yuting and Tarokh, Vahid},
booktitle={2024 Winter Simulation Conference (WSC)},
title={Perceiving Copulas for Multimodal Time Series Forecasting},
year={2024},
volume={},
number={},
pages={690-701},
keywords={Limiting;Computational modeling;Time series analysis;Focusing;Transforms;Predictive models;Transformers;Encoding;Forecasting;Distribution functions},
doi={10.1109/WSC63780.2024.10838953}}