CATE Estimation With Potential Outcome Imputation From Local Regression
Abstract
The work tackles a core issue in conditional average treatment effect (CATE) estimation: distributional mismatch between treatment groups. It introduces a model‑agnostic counterfactual data augmentation method that first derives regret bounds suggesting that small, carefully controlled imputation error can be beneficial. Using a contrastive learning scheme, the method imputes reliable missing potential outcomes for a selected subset of units (selected by a similarity rule), augments the dataset with these imputations to reduce group discrepancy, and then trains standard CATE estimators on the augmented data. Theory and extensive experiments show improved accuracy and robustness across many CATE models.
TL;DR: The paper tackles the challenge of estimating Conditional Average Treatment Effects (CATE) when there's a statistical imbalance between treatment groups. It introduces a model-agnostic counterfactual data augmentation method using contrastive learning to learn a representation space where similar individuals have similar potential outcomes.
Key Ideas
- Regret bounds motivate when/why limited imputation error can aid CATE estimation.
- Contrastive imputation reliably imputes missing potential outcomes for a subset selected via similarity.
- Model‑agnostic augmentation plugs into common CATE learners after reducing cross‑group discrepancy.
Method Sketch
- Compute a local similarity neighborhood for each unit via regression/local metrics.
- Use contrastive learning to impute missing potential outcomes for a reliable subset.
- Augment the dataset with these counterfactuals and train any downstream CATE model.
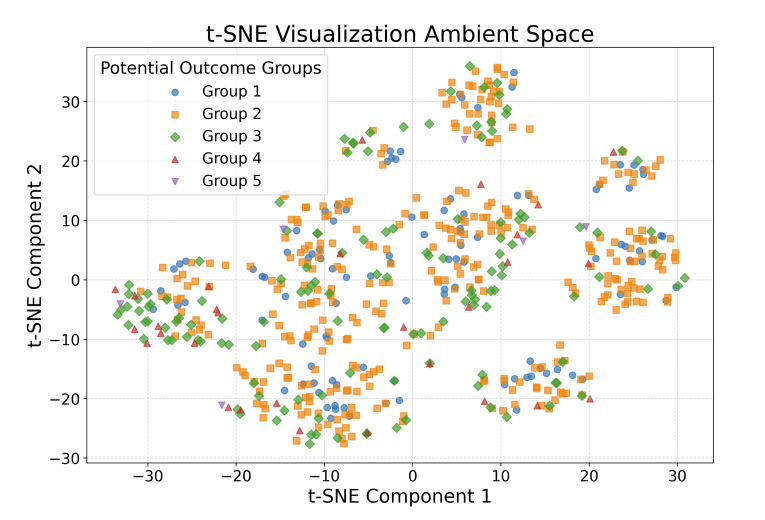 t-SNE visualization of IHDP features and potential outcome Y0 in the ambient space.
t-SNE visualization of IHDP features and potential outcome Y0 in the ambient space.
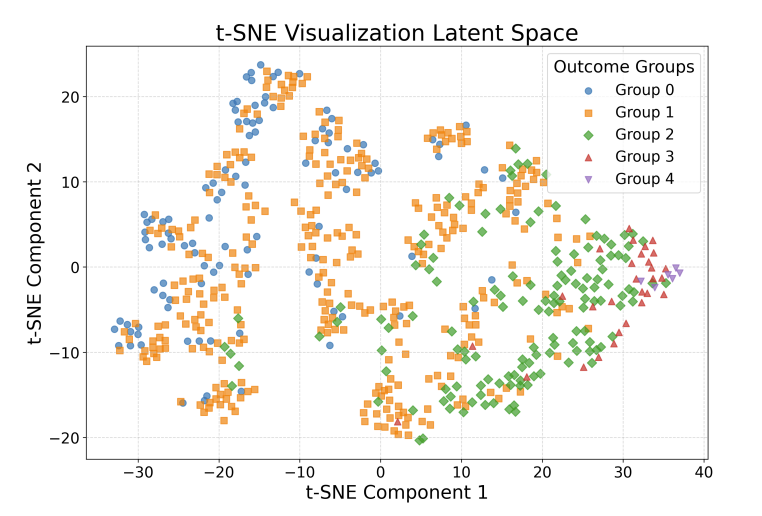 t-SNE visualization of IHDP features and potential outcome Y0 in the latent space.
t-SNE visualization of IHDP features and potential outcome Y0 in the latent space.
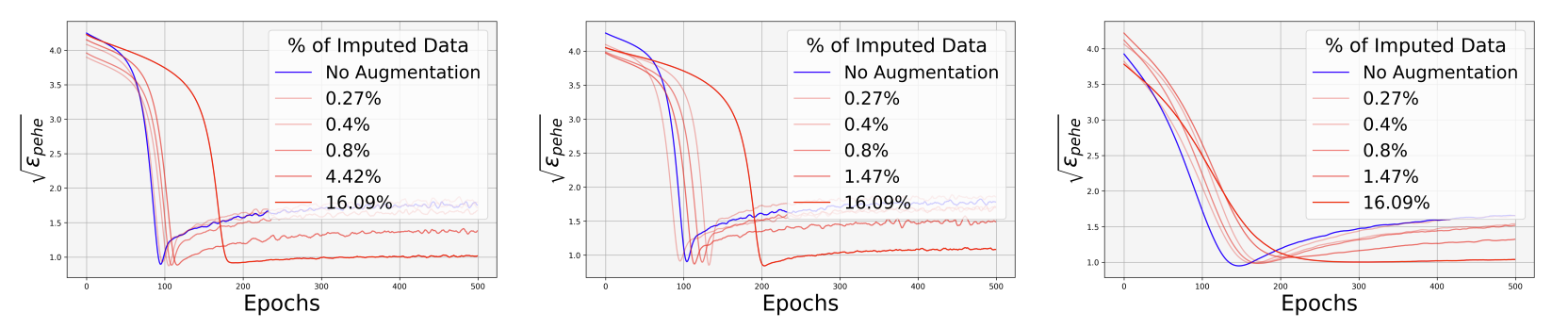 Effects of COCOA on preventing overfitting. From left to right: IHDP with TARNet, CFR-Wass, and T-learner.
Effects of COCOA on preventing overfitting. From left to right: IHDP with TARNet, CFR-Wass, and T-learner.
Experiments (at a glance)
The paper reports consistent gains on standard semi‑synthetic and benchmark setups for CATE, showing robustness across multiple base estimators. Improvements hold especially where treatment/control distributions differ substantially.
Citation
@inproceedings{10.5555/3762387.3762391,
author = {Aloui, Ahmed and Dong, Juncheng and Le, Cat P. and Tarokh, Vahid},
title = {CATE estimation with potential outcome imputation from local regression},
year = {2025},
publisher = {JMLR.org},
booktitle = {Proceedings of the Forty-First Conference on Uncertainty in Artificial Intelligence},
articleno = {4},
numpages = {27},
location = {Rio de Janeiro, Brazil},
series = {UAI '25}
}